
バックエンドエンジニア(データ基盤開発)















エンジニア組織について

データ戦略部門の開発体制とプロセス
フロント、バックエンド、インフラなどの領域に応じた特別なロールはなく、得意なメンバーを中心に皆で分担しています。

スクラムをベースとしたアジャイル開発を行っており、多くのチームが1週間のスプリントを回しています。
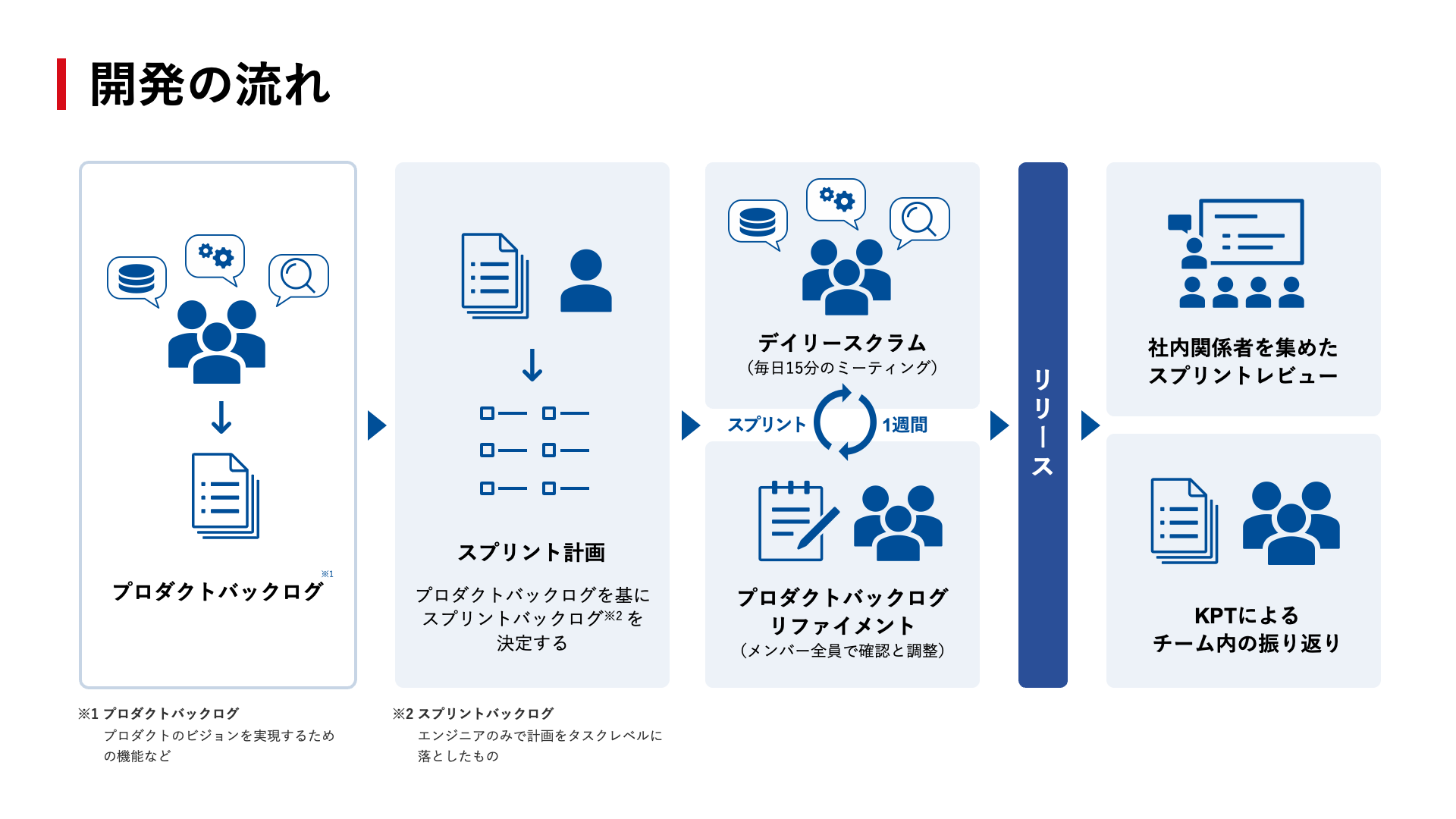
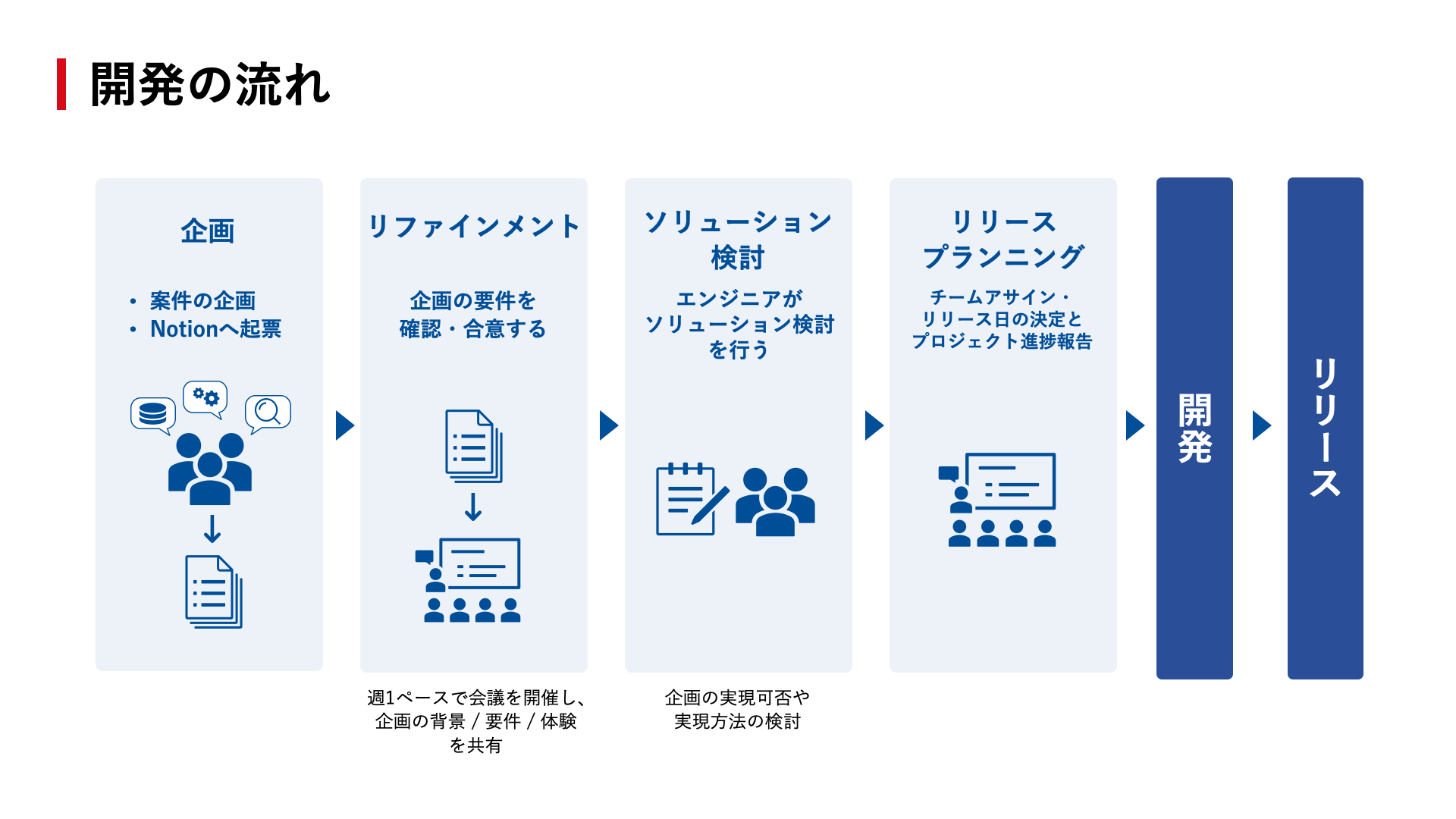
設計や技術選定の流れ
各チームでデータを見ながらディスカッションして決めます。
データは、自前で収集した企業データや人事異動情報に加え、各プロダクトから集まるユーザーデータも含めて膨大な量のデータを扱っています。
設計や技術選定のプロセスにおいては、ロジックやアーキテクチャの検証のためにそれらのデータを再現したステージング環境を用いて、仮説の精度や非機能要件を確認し、フィージビリティ調査しています。
代表的な1日のスケジュール
Nayose Group所属のWebエンジニアの代表的な1日のスケジュールです。この日は在宅勤務です。





12:00 ~ 13:00 昼休憩
出社メンバー同士で昼食したり、在宅メンバーは家族やペットと共に昼休憩









フレームワークやライブラリのバージョンアップへの考え方
セキュリティリスクの解消や、新機能を利用することによる開発生産性や開発者体験の向上を目指して、できるだけ最新バージョンを利用することが望ましいと考えています。
大型バージョンアップ直後は不安定な可能性もあるリスクや、機能開発タスクの進捗などとバランスを取りながら、日々の運用やクォーター単位で作業計画して取り組んでいます。
技術的負債の解消に向けた取り組み
短期間で解消できるものは、普段のスプリントの中で随時対応して、改善しています。
一方、規模の大きな取り組みになる場合、ビジネスサイドと優先度のすり合わせを行い、OKRに組み込む活動をしています。直近でも、デプロイ方式の刷新や、各プロダクトとのデータ連携方式の変更などに取り組みました。
データ戦略部門 紹介資料
Pick Up コンテンツ

ビジネスデータに可能性を感じている人と 「データ戦略部」で一緒に働きたい
技術本部 Sansan Engineering Unit Master Dataグループ 松本 清紀

技術本部データ戦略部、マスターデータグループエンジニアの松本清紀にインタビューを行いました。2年前の入社時からやりたいと思っていたことに今ようやく集中して取り組める環境が整ったとこと。「データ戦略部」のエンジニアならではの面白さとは。
続きを読む
※記事内の組織名称は、2022年7月時点のもの
データ戦略部門 技術スタック
| Category | 名寄せ | 人物・企業情報収集・配信 | データ化 | データ統合 |
|---|---|---|---|---|
| Programming Language / Library etc. | Frontend Ruby on Rails (ERB) | Frontend TypeScript, React | Frontend TypeScript, React | Frontend TypeScript, Next.js (React) |
| Backend Ruby on Rails,Rust(Rustは「共通正規化処理ライブラリ開発」で使用) | Backend Ruby on Rails | Backend Go, Echo | Backend TypeScript (NestJS) | |
| Infrastructure | AWS(ECS, S3, SQS 他), GCP(Bigquery) | AWS(EC2, ECS, S3, SQS 他) | AWS(EC2, ECS, S3, SQS 他) | AWS (ECS, S3, SQS 他), GCP (GCS, Dataform, Pub/Sub, CloudRun 他) |
| Database | Aurora MySQL, OpenSearch Service, Redshift, DynamoDB, CloudSQL, BigQuery |
|---|---|
| 利用ツール | Docker, Terraform, GitHub, CircleCI, Datadog, Sentry, Notion, Slack, Copilot 他 |
| 開発支援 生成AIツール | Gemini, Copilot, Claude Code, Cursor など(利用条件や利用用途に応じて適宜判断) |